창의IT설계는 우리 학과의 간판 과목으로 한 학기 동안 자유 주제로 자신이 “창의IT스럽다”고 생각하는 프로젝트를 진행하는 과목이다. 총 네 단계로 이루어져 있으며 1, 2는 팀으로, 3, 4는 개인으로 진행하며 1, 2에서는 학기별로 주제를 변경하고 3, 4는 한 주제를 1년동안 진행하는 경우가 많다. 나는 자신이 원하는 프로젝트를 마음대로 진행할 수 있다는 자율성과, 학점을 통한 압박으로 마냥 놀지 못하게 하는 강제성이 절묘하게 시너지를 내는 훌륭한 과목이라고 생각한다. 창의IT융합공학과 진학을 선택하면서 고려했던 것도, 어차피 어느 학교에 가든 관심 있는 기술들을 바탕으로 개인 프로젝트를 진행할텐데 창의IT설계 과목 덕분에 주마다 프로젝트 진행 시간도 보장해주고 학점까지 챙겨갈 수 있으니 훨씬 집중하기 쉬운 환경이라고 생각했었다. 장학금 덕분에 신경 쓸 부분이 적어진다는 점도 마음에 들었었다.
사실 앞 문단은 은근슬쩍 끼워 넣은 학과 홍보였고, 본론으로 들어가면 학기 시작이 다가오면서 창의IT설계 3, 4 주제 선정 때문에 고민하고 있다. 교수님들께서는 방학 때 프로젝트를 시작하는 것을 추천하시지만 대부분의 학생들이 학기가 시작하고 프로젝트를 시작한다. 동아리에서 해킹을 하면서 기존 디버거들에 느꼈던 불만을 바탕으로 창의IT설계 3, 4에서는 바이너리 분석 및 디버깅 플랫폼을 주제로 하려고 생각하고 있었다. 시각적으로 좋은 프로젝트와 일상생활과 연관이 있는 프로젝트가 점수를 잘 받는 경향이 있기 때문에 학점 측면에서는 도박성이 있는 주제 선정이지만, 내가 즐겁게 할 수 있으면서 배우는 게 많고, 커리어에도 도움이 될 거라 생각해 이 주제를 일순위로 고려중이었다.
내가 해결하고 싶었던 문제들은 다음과 같다.
- 디버깅 도구들의 높은 러닝 커브 낮추기
- 바이너리 분석과 페이로드 제작 환경 통합
- 중간 언어를 이용한 멀티 아키텍처 디컴파일링
- codemap, qira, angr 등에 대한 쓰기 쉬운 프론트엔드 제공, 혹은 유사 기능 구현해 통합
주요 고려 대상이었던 건 gdb와 IDA 두 가지였다. gdb는 CUI에서 기반하는 명령어 암기 및 높은 러닝 커브가 문제라 생각했고, IDA는 높은 가격과 강력한 기능에 비해 아쉬운 UX(Undo 미지원 등)를 개선하고 싶었다. 또한 IDA처럼 실행 환경(주로 Unix)과 분석환경(주로 Windows)이 달라서 생기는 사소한 문제들도 해결할 수 있으면 좋겠다고 생각했다.
하지만 당연히 비슷한 생각을 하는 사람들이 있어서, Binary Ninja나, radare2 같은 2티어 바이너리 분석 툴들에서 이미 비슷한 문제에 대해 고민하고 있었다. 특히 radare2 같은 경우는 해외 커뮤니티에서 super stiff learning curve라는 이야기를 들을 정도로 어디서부터 시작하면 좋을지 모르게 생겼었는데, 최근에 웹 UI를 도입하면서 사용성이 크게 개선된 것처럼 보였다.
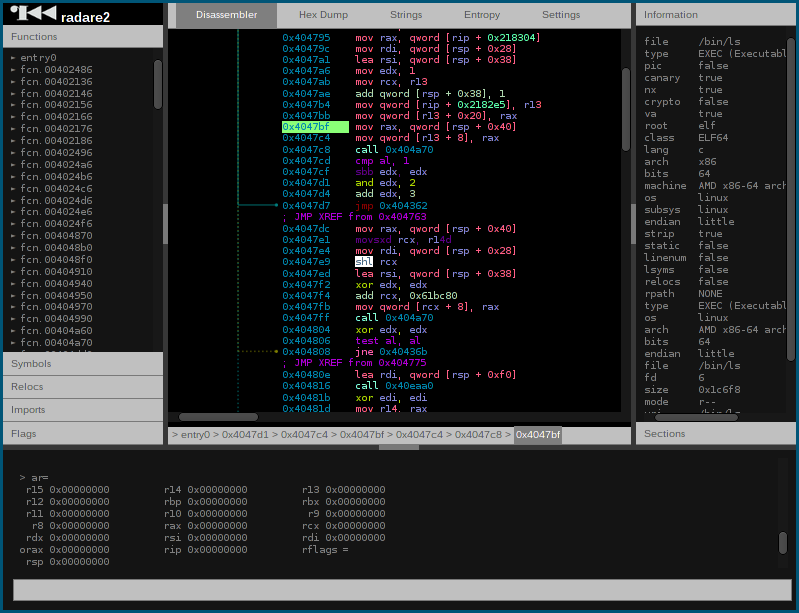
내가 생각하고 있던 구조도 서버에서 바이너리를 실행하고 웹 기반 GUI로 상호작용 하는 것이었는데, radare2의 웹 UI와 특징이 많이 겹쳤다. Binary Ninja는 웹UI는 아니지만 이것도 쓰기 좋은 크로스 플랫폼 UI를 제공하기 때문에 UI 사용성에서는 크게 우위를 보이기 힘들 것이라는 생각이 들었다.
중간 언어를 이용한 디컴파일링 기능은 Hex-Rays 만큼은 당연히 구현하지 못하겠지만, 함수 시그니처 인식, 조건문과 반복문 정도만 구현해도 무료 도구 치고는 경쟁력을 가질 수 있다고 생각했다. 하지만 radare2에서 이미 구현중이었고, Binary Ninja의 로드맵에도 주 목표 중 하나로 제시되어 있었다. 조사하다보니 lldb, gdb, vdb, windbg에 대한 추상화 레이어를 제공하는 Voltron 같은 프로젝트도 있었고, 알아볼수록 기존에 잘 만든 도구들이 많아서 이 주제를 그대로 고르는 것이 맞는지 계속 고민된다. 만약 그대로 이 주제를 선택한다면 완성도는 Binary Ninja Python Prototype 정도를 목표로 하려고 한다. 또한, 기존 도구들에 비해 어떤 차별성을 가질 수 있을지를 더 심도있게 고민해야 할 것으로 보인다.
만약의 경우를 대비해 생각해 두고 있는 다른 주제들도 몇 개 있다. 첫 번째는 1학년 때 MS 이매진컵 주제였던 복셀 기반 월드 에디터 + 비주얼 프로그래밍 언어를 이용한 교육용 프로그래밍 플랫폼 프로젝트다. SangJa라는 이름으로 나갔었는데, JS가 처음이기도 했고 협업에 익숙하지 않아 코드 관리가 조금 아쉬웠지만 주제 자체는 훌륭했다고 생각한다. 지금 생각하고 있는 주제 중 “창의IT”에 제일 적합하다고 생각되기는 한다. 팀 프로젝트라 내가 마음대로 주제를 쓸 수 있는게 아니라서 만약 이 주제를 고르게 된다면 이전에 같이 진행했던 사람들에게 연락해 내가 주제를 다시 써도 되는지 물어보아야 할 것 같다.
두 번째 주제는 안드로이드 매크로다. G매크로류의 매크로 프로그램들은 PC만 지원하는 경우가 많은데, 안드로이드까지 지원을 확장하고 비전 기반 기능들을 추가하려고 생각하고 있다(체력바를 읽는다든지 카드 희귀도를 알아내서 리세마라를 해 준다든지). 이 주제를 하게 되면 본의 아니게 또 OpenCV와 한 학기를 보내게 될 것이다. 이것도 적다보니 오토핫키 안드로이드 열화 카피가 되는 건 아닌지 걱정된다. sl4a 같은 프로젝트도 있고…
원래는 미리 고민해서 개발을 시작하려고 했는데, 연구참여도 하고 동아리도 하다 보니 짧은 방학이 훌쩍 지나가버렸다. 이번 학기에는 기초필수 과목이 끝난 덕분에 학기중 연참을 하면서 창의IT설계와 연구참여 투탑 체제로 프로그래밍 비중이 높은 학기를 보내려고 계획하고 있다.

 로 나누어 떨어지는지 확인한다. 가로 분할선과 세로 분할선의 위치는 초콜릿 개수를 통해 독립적으로 판단 가능하며, 분할선들의 위치가 정해지면 분할된 각 칸에 초콜릿이 균등하게 들어가 있는지 확인한다.
로 나누어 떨어지는지 확인한다. 가로 분할선과 세로 분할선의 위치는 초콜릿 개수를 통해 독립적으로 판단 가능하며, 분할선들의 위치가 정해지면 분할된 각 칸에 초콜릿이 균등하게 들어가 있는지 확인한다.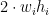 를 미리 P에서 빼고, 물건의 크기가
를 미리 P에서 빼고, 물건의 크기가  점수는
점수는 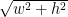 인 냅색을 수행한다.
인 냅색을 수행한다.