오랜만의 블로그 포스트가 알고리즘 대회 후기가 될 것이라고 예상하지 못했는데, 마지막 글이 올라온지도 꽤 됐고 이번 대회에서 하고 싶은 얘기도 있어서 포스팅을 하기로 했다. 현재 나는 작년 ICPC 이후로 공식적으로는 경쟁 프로그래밍을 은퇴한 상태다. 평소에 공부하고 시간 쓰는건 완전히 멈췄고, 대신 거기 쓰던 시간을 워게임 등 해킹 문제를 풀거나 졸업 후 진로 준비에 쓰고 있다. 이렇게 말하니까 알고리즘 공부에 계속 시간을 많이 쓰고 노력했던 것 같지만 은퇴 선언 이전에도 실질적으로 손을 놓은지는 꽤 됐다. 지금은 티셔츠나 상금 등 부상 주는 대회를 가끔 부담 없이 나가는 걸 목표로 하고 있다.
원래 이번 코드잼은 Rust로 알고리즘 라이브러리를 짜고 그걸 써서 대회를 치고, 대회와 대회 사이에 라이브러리를 보강한 뒤 대회 이후 프로젝트를 다듬어서 공개한다는 원대한 계획과 함께하고 있었다. 하지만 코드잼 플랫폼이 바뀌고 Rust가 지원 언어 목록에 없어서 라이브러리 작성에 대한 관심이 급격하게 식었고, 다익스트라 알고리즘 정도만 겨우 구현된 Rust 알고리즘 라이브러리는 지금까지 존재했던 나만 알고 있다가 비트의 저편으로 사라졌던 많은 개인 프로젝트와 마찬가지로 GitHub 개인 저장소에 조금 더 머무르다 영영 사라질 예정이다. Cargo 배포용으로 이름도 지어줬는데 불쌍한 친구…
올해 코드잼 연습 세션을 치고 나서 느꼈던 건 생각하는 능력 자체는 예상보다 덜 줄었고, 전통적인 테크닉을 떠올리거나 코드를 빠르게 짜는 능력은 예상보다 많이 줄었다는 거였다. 여기서 “생각하는 능력”은 연습 세션 3번 Steed 2 Cruise Control에서 여러 속도로 달리는 말들 사이의 불변조건을 구하는 능력을 말하고 “전통적인 테크닉”은 R1A 3번 Edgy Baking을 보고 냅색이니까 DP로 풀면 뚝딱 할 수 있겠다는 걸 떠올리는 능력을 말한다. 연습 세션부터 이번 R1A까지 예전에 비해 같은 코드를 짜는데 시간이 훨씬 오래 걸린다는게 느껴졌다.
이번 대회를 치면서 좀 놀랐던 점은 대회 중 오랜만에 초심을 되찾은 기분을 느꼈던 것이다. 내 풀이에서 놓친 점을 찾았을 때 예전 같았으면 쉬운 문제에서 실수했다고 자책했겠지만 이번 대회에서는 웬일로 풀이의 빠진 구멍을 채워 나가는 느낌이 즐겁게 느껴졌다. 알고리즘 대회에서 어려운 문제에 도전하는 지적 만족감을 느낀 적은 많았지만, 문제를 푸는 것이 아니라 시간 제한을 두고 대회를 치는 것을 즐겁다고 생각해 본지는 꽤 오래됐다. 평소에 연습을 많이 안 하니 예전만큼 잘하지 못하는 건 당연하다고 생각하면서도 무의식 속에서는 그래도 내가 경력이 얼마인데 못해도 어느 정도는 해야 한다는 부담을 느끼고 있었다고 생각한다. 나도 내가 무의식에서 어떤 생각을 하는지 완전히 모르지만, 공식적으로 은퇴했다고 선언했던게 그런 부담을 낮춰준 게 아닌가 추측하고 있다. 바뀐 플랫폼에서 스코어보드가 문제 페이지에 보이지 않는 것도 도움이 됐다.
원래 대회 후기는 문제 풀이도 함께 올리는게 전통이므로 간단한 풀이도 함께 첨부한다.
- A: 전체 초콜릿 개수를 세고,
로 나누어 떨어지는지 확인한다. 가로 분할선과 세로 분할선의 위치는 초콜릿 개수를 통해 독립적으로 판단 가능하며, 분할선들의 위치가 정해지면 분할된 각 칸에 초콜릿이 균등하게 들어가 있는지 확인한다.
- B: 계산이 특정 시간 안에 끝날 수 있는지를 판단하는 판별 함수를 작성하고 파라메트릭 바이너리 서치를 수행한다. 판별 함수는 각 계산원이 그 시간까지 처리 가능한 비트의 수를 계산한 뒤 정렬해 큰 순서대로 R개를 뽑아 B 이상이면 처리 가능한 것이다.
- C: 0-1 냅색.
를 미리 P에서 빼고, 물건의 크기가
점수는
인 냅색을 수행한다.
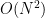 으로 Large input이 풀리기 때문에 특별히 자료구조를 쓸 필요도 없다.
으로 Large input이 풀리기 때문에 특별히 자료구조를 쓸 필요도 없다.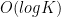 만에 해결 가능하다. 한 가지 관찰이 필요한데, 반씩 줄여 나가는 방식으로 시뮬레이션 하더라도 어떤 시점에서 구간의 크기의 종류가 최대 두 종류라는 사실이다. (n) -> (a, a+1) -> (b, b+1)과 같이 연속한 두 수에 대해서만 관리하면 되고, atomic하게 처리하지 않는 경우에도 최대 네 종류만 관리하면 된다. 탐색 최대 크기가 작아 굳이 Balanced Binary Tree를 쓸 필요는 없었지만 코딩하기 귀찮아서 set을 발라서 해결했다.
만에 해결 가능하다. 한 가지 관찰이 필요한데, 반씩 줄여 나가는 방식으로 시뮬레이션 하더라도 어떤 시점에서 구간의 크기의 종류가 최대 두 종류라는 사실이다. (n) -> (a, a+1) -> (b, b+1)과 같이 연속한 두 수에 대해서만 관리하면 되고, atomic하게 처리하지 않는 경우에도 최대 네 종류만 관리하면 된다. 탐색 최대 크기가 작아 굳이 Balanced Binary Tree를 쓸 필요는 없었지만 코딩하기 귀찮아서 set을 발라서 해결했다.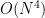 으로 사각형 두 개를 잡아서 루프를 돌며 세는 문제라고 생각했으나, 원 영역에 애매하게 걸치는 바람에 이동 후 사각형 밖에 존재하게 되어 버리는 점이 생기지 않는지를 엄밀하게 검증하기 싫어서 Beach Umbrellas 문제로 넘어갔다. 맞은 분들 솔루션 보니까 처음 생각한대로 풀면 되는 것 같다. 대회 끝나고 후기를 퇴고하면서 항상 가능하다는 걸 보였는데, 원 반지름을 무한으로 보내서 사각형이 겹치지 않는 경우 그 사이에 선을 긋고(여기까진 대회 도중 생각했다), 겹치는 경우에는 교점 두 개를 대상으로 선을 그어 공간을 분할하면 항상 사각형 두 개를 고르는 경우로 치환 가능하다는 걸 알게 되었다.
으로 사각형 두 개를 잡아서 루프를 돌며 세는 문제라고 생각했으나, 원 영역에 애매하게 걸치는 바람에 이동 후 사각형 밖에 존재하게 되어 버리는 점이 생기지 않는지를 엄밀하게 검증하기 싫어서 Beach Umbrellas 문제로 넘어갔다. 맞은 분들 솔루션 보니까 처음 생각한대로 풀면 되는 것 같다. 대회 끝나고 후기를 퇴고하면서 항상 가능하다는 걸 보였는데, 원 반지름을 무한으로 보내서 사각형이 겹치지 않는 경우 그 사이에 선을 긋고(여기까진 대회 도중 생각했다), 겹치는 경우에는 교점 두 개를 대상으로 선을 그어 공간을 분할하면 항상 사각형 두 개를 고르는 경우로 치환 가능하다는 걸 알게 되었다.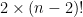 을 곱해 차례로 더하면 된다.
을 곱해 차례로 더하면 된다.
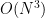 이라서 망한 문제다. 최적화 하려면 할 수는 있는 부분이었지만 6분만에 익숙하지 않은 언어로 고치기는 불가능했다. 다행히 6분은 꽤 길기 때문에 시간 내에 답이 나올듯 말듯 진행됐는데, 30초쯤 남았을 때 95번 정도고 마지막에 최대 크기 데이터가 몰려 있는걸 보고 포기하고 코드 전시라도 하자 싶어서 그 때까지의 출력을 복사한 다음 뒤쪽을 다 0으로 채운
이라서 망한 문제다. 최적화 하려면 할 수는 있는 부분이었지만 6분만에 익숙하지 않은 언어로 고치기는 불가능했다. 다행히 6분은 꽤 길기 때문에 시간 내에 답이 나올듯 말듯 진행됐는데, 30초쯤 남았을 때 95번 정도고 마지막에 최대 크기 데이터가 몰려 있는걸 보고 포기하고 코드 전시라도 하자 싶어서 그 때까지의 출력을 복사한 다음 뒤쪽을 다 0으로 채운  제한 조건으로 같은
제한 조건으로 같은  풀이임에도 불구하고 통과가 되는 풀이가 있고 아닌 풀이가 있었기 때문이지만 “호호 여러분들 엔제곱 풀이를 생각하셨나 봐요” 같은 투로 말씀하셔서 여기서도 대회측이 참가자들의 여론을 잘 파악하지 못하고 있다는 것을 느꼈다. 설문조사에 이런 부분을 담으려고 노력했지만 잘 전달되었는지는 모르겠다.
풀이임에도 불구하고 통과가 되는 풀이가 있고 아닌 풀이가 있었기 때문이지만 “호호 여러분들 엔제곱 풀이를 생각하셨나 봐요” 같은 투로 말씀하셔서 여기서도 대회측이 참가자들의 여론을 잘 파악하지 못하고 있다는 것을 느꼈다. 설문조사에 이런 부분을 담으려고 노력했지만 잘 전달되었는지는 모르겠다.