시작할 때는 컨디션이 좋아서 빠르게 A, C를 풀었지만 B에서 삽질을 많이 하면서 4 WA(…)를 받았다. 심지어 system test에서 B Large가 나갔다. 436위로 마무리. R2 액땜했다고 생각하자.
A
ZERO, ONE, TWO, THREE, …, NINE으로 이루어진 아나그램을 주고, 각 숫자를 몇 번씩 사용했는지 출력하는 문제다. 0, 2, 4, 6, 8, 1, 5, 3, 7, 9 순서로 그리디하게 빼 주면 유일해를 쉽게 찾을 수 있다. 구조화를 잘못해서 코드를 몇 번 지우고 다시 짜서 문제 난이도에 비해 코딩이 오래 걸렸다.
#include <cstdio>
#include <cstring>
#include <algorithm>
const int MAX = 2999;
using namespace std;
int countAlphabet[99], countDigit[10][99], usedDigit[10];
char * digitName[] = {
"ZERO", "ONE", "TWO", "THREE", "FOUR", "FIVE", "SIX", "SEVEN", "EIGHT", "NINE"
};
void countNumber(char * str) {
for (int i = 0; str[i]; i++)
countAlphabet[str[i] - 'A']++;
}
void greedyUse(int digit) {
int maxUse = MAX;
for (char abc = 'A'; abc <= 'Z'; abc++) {
if (countDigit[digit][abc - 'A'])
maxUse = min(maxUse, countAlphabet[abc - 'A'] / countDigit[digit][abc - 'A']);
}
usedDigit[digit] += maxUse;
for (char abc = 'A'; abc <= 'Z'; abc++) {
countAlphabet[abc - 'A'] -= maxUse * countDigit[digit][abc - 'A'];
}
}
int main() {
freopen("output.txt", "w", stdout);
for (int i = 0; i < 10; i++) {
for (int j = 0; digitName[i][j]; j++) {
countDigit[i][digitName[i][j] - 'A']++;
}
}
int numCase, nowCase;
scanf("%d", &numCase);
for (nowCase = 1; nowCase <= numCase; nowCase++) {
memset(countAlphabet, 0, sizeof(countAlphabet));
memset(usedDigit, 0, sizeof(usedDigit));
char str[MAX];
scanf("%s", str);
countNumber(str);
greedyUse(0); //Zero
greedyUse(2); //tWo
greedyUse(4); //foUr
greedyUse(6); //siX
greedyUse(8); //eiGht
//absoulute greedy
greedyUse(1); //One
greedyUse(5); //Five
greedyUse(3); //THRee
greedyUse(7); //SeVen
greedyUse(9); //NINE
//relative greedy
printf("Case #%d: ", nowCase);
for (int digit = 0; digit < 10; digit++) {
for (int i = 0; i < usedDigit[digit]; i++)
printf("%d", digit);
}
puts("");
}
return 0;
}
26:58 AC
C
B가 내가 약한 문제 유형이라 C부터 풀기로 했다. string을 정점으로 변환한 뒤 이분 그래프에서 minimum vertex cover를 찾으면 된다. 이분매칭을 너무 오랜만에 짜서 검색하느라 오래 걸렸지만 문제 자체는 알면 쉽다.
#include <cstdio>
#include <iostream>
#include <map>
#include <string>
#include <vector>
const int MAX = 1020;
using namespace std;
int fCount, sCount;
map < string, int > fWord, sWord;
int n, crossS[MAX];
bool visitS[MAX];
vector < int > edges[MAX];
bool dfs(int f) {
for (int s : edges[f]) {
if (!visitS[s]) {
visitS[s] = 1;
if (crossS[s] < 0 || dfs(crossS[s])) {
crossS[s] = f;
return true;
}
}
}
return false;
}
int bipartiteMatch() {
int ret = 0;
memset(crossS, -1, sizeof(crossS));
for (int f = 0; f < fCount; f++) {
memset(visitS, 0, sizeof(visitS));
if (dfs(f)) {
ret++;
}
}
return ret;
}
int main() {
freopen("output.txt", "w", stdout);
ios::sync_with_stdio(true);
int numCase, nowCase;
scanf("%d", &numCase);
for (nowCase = 1; nowCase <= numCase; nowCase++) {
fWord.clear();
sWord.clear();
for (int i = 0; i < fCount; i++)
edges[i].clear();
fCount = sCount = 0;
scanf("%d", &n);
for (int i = 0; i < n; i++) {
string fStr, sStr;
cin >> fStr >> sStr;
int fIndex, sIndex;
if (fWord.find(fStr) == fWord.end()) {
fWord[fStr] = fCount;
fIndex = fCount;
fCount++;
} else {
fIndex = fWord[fStr];
}
if (sWord.find(sStr) == sWord.end()) {
sWord[sStr] = sCount;
sIndex = sCount;
sCount++;
} else {
sIndex = sWord[sStr];
}
edges[fIndex].push_back(sIndex);
}
int numMatch = bipartiteMatch();
printf("Case #%d: %d\n", nowCase, n - (fCount + sCount - numMatch));
}
return 0;
}
58:57 AC
B
내가 잘 풀지 못하는 유형이라 생각하고 넘기고 풀었는데, 정말로 잘 못 푸는 유형이라 4번의 오답 끝에 small을 맞출 수 있었다. Large는 푼 줄 알았는데 system test에서 틀렸다.
문자열 두 개 모두 ?가 아니면서 서로 다른 위치 중 가장 앞에 있는 위치를 찾는다. 존재하지 않는 경우는 두 점수를 동일하게 만들 수 있다. 존재하는 경우는 그 위치를 기준으로 뒤쪽은 모두 0 또는 9로 채우고, 앞쪽을 최대한 비슷하게 만들면 된다.
PL 수업을 수강하면서 코드 설계력이 좋아지고 버그를 내는 빈도가 줄었다고 생각하고 있었는데, B 코드는 확실히 설계는 잘 한 것 같은데 사소한 버그를 너무 많이 내서 슬펐다. 값 비교할 때 절댓값을 취하지 않는다든가, break을 잊었다든가 하는 실수를 4번이나 저질렀다고 한다…
아래 코드는 small만 통과한다. ??8? ?02?는 0989 1020가 나와야 하는데 0089 0029가 나온다. ‘앞 부분을 최대한 비슷하게’ 하는 방법이 틀렸음.
#include <cstdio>
#include <cstring>
#include <string>
const int MAX = 20;
using namespace std;
typedef long long ll;
void makeSame(char *a, char *b, int n) {
for (int i = 0; i < n; i++) {
if (a[i] == '?') {
if (b[i] == '?') {
a[i] = b[i] = '0';
} else {
a[i] = b[i];
}
} else {
if (b[i] == '?') {
b[i] = a[i];
}
}
}
}
void fill(char c, char *s, char *end) {
while (s != end) {
if (*s == '?') *s = c;
s++;
}
}
bool inc(char *s, char *tpl, int n) {
for (int i = n-1; i >= 0; i--) {
if (tpl[i] == '?') {
if (s[i] == '9') {
s[i] = '0';
} else {
s[i]++;
return true;
}
}
}
return false;
}
bool dec(char *s, char *tpl, int n) {
for (int i = n-1; i >= 0; i--) {
if (tpl[i] == '?') {
if (s[i] == '0') {
s[i] = '9';
} else {
s[i]--;
return true;
}
}
}
return false;
}
int main() {
freopen("output.txt", "w", stdout);
int numCase, nowCase;
scanf("%d", &numCase);
for (nowCase = 1; nowCase <= numCase; nowCase++) {
int n;
char f[MAX], s[MAX];
char rf[MAX], rs[MAX];
scanf("%s%s", f, s);
n = strlen(f);
int diff = -1;
for (int i = 0; i < n; i++) {
if (f[i] != '?' && s[i] != '?' && f[i] != s[i]) {
diff = i;
break;
}
}
if (diff == -1) {
//can be same
makeSame(f, s, n);
strcpy(rf, f);
strcpy(rs, s);
} else {
ll fsDiff = 1e18;
auto update = [&](char *fCand, char *sCand) {
ll rfCand = atoll(fCand);
ll rsCand = atoll(sCand);
ll candDiff = abs(rsCand - rfCand);
if (fsDiff > candDiff ||
(fsDiff == candDiff &&
(atoll(rf) > rfCand || (atoll(rf) == rfCand && atoll(rs) > rsCand)))) {
strcpy(rf, fCand);
strcpy(rs, sCand);
fsDiff = candDiff;
}
};
char tf[MAX], ts[MAX];
if (f[diff] < s[diff]) {
//f < s
strcpy(tf, f);
strcpy(ts, s);
makeSame(tf, ts, diff);
fill('9', tf+diff, tf+n);
fill('0', ts+diff, ts+n);
update(tf, ts);
//f > s
strcpy(tf, f);
strcpy(ts, s);
makeSame(tf, ts, diff);
if (inc(tf, f, diff)) {
fill('0', tf+diff, tf+n);
fill('9', ts+diff, ts+n);
update(tf, ts);
}
//f > s
strcpy(tf, f);
strcpy(ts, s);
makeSame(tf, ts, diff);
if (dec(ts, s, diff)) {
fill('0', tf+diff, tf+n);
fill('9', ts+diff, ts+n);
update(tf, ts);
}
} else {
//f > s
strcpy(tf, f);
strcpy(ts, s);
makeSame(tf, ts, diff);
fill('0', tf+diff, tf+n);
fill('9', ts+diff, ts+n);
update(tf, ts);
//f < s
strcpy(tf, f);
strcpy(ts, s);
makeSame(tf, ts, diff);
if (inc(ts, s, diff)) {
fill('9', tf+diff, tf+n);
fill('0', ts+diff, ts+n);
update(tf, ts);
}
//f < s
strcpy(tf, f);
strcpy(ts, s);
makeSame(tf, ts, diff);
if (dec(tf, f, diff)) {
fill('9', tf+diff, tf+n);
fill('0', ts+diff, ts+n);
update(tf, ts);
}
}
}
//printf("%s %s\n", f, s);
printf("Case #%d: %s %s\n", nowCase, rf, rs);
}
return 0;
}
2:03:41 small AC
 에 동작함이 증명되어 있습니다. 아래는 각 알고리즘의 설명과 구현 코드입니다. 입출력은 BOJ의
에 동작함이 증명되어 있습니다. 아래는 각 알고리즘의 설명과 구현 코드입니다. 입출력은 BOJ의 
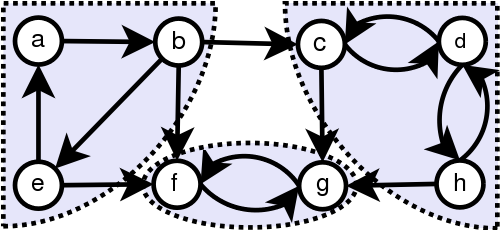
 에 대해 두 개의 정점
에 대해 두 개의 정점  을 생성합니다.
을 생성합니다. 에 대해,
에 대해, 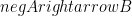 간선과
간선과  간선을 생성합니다.
간선을 생성합니다.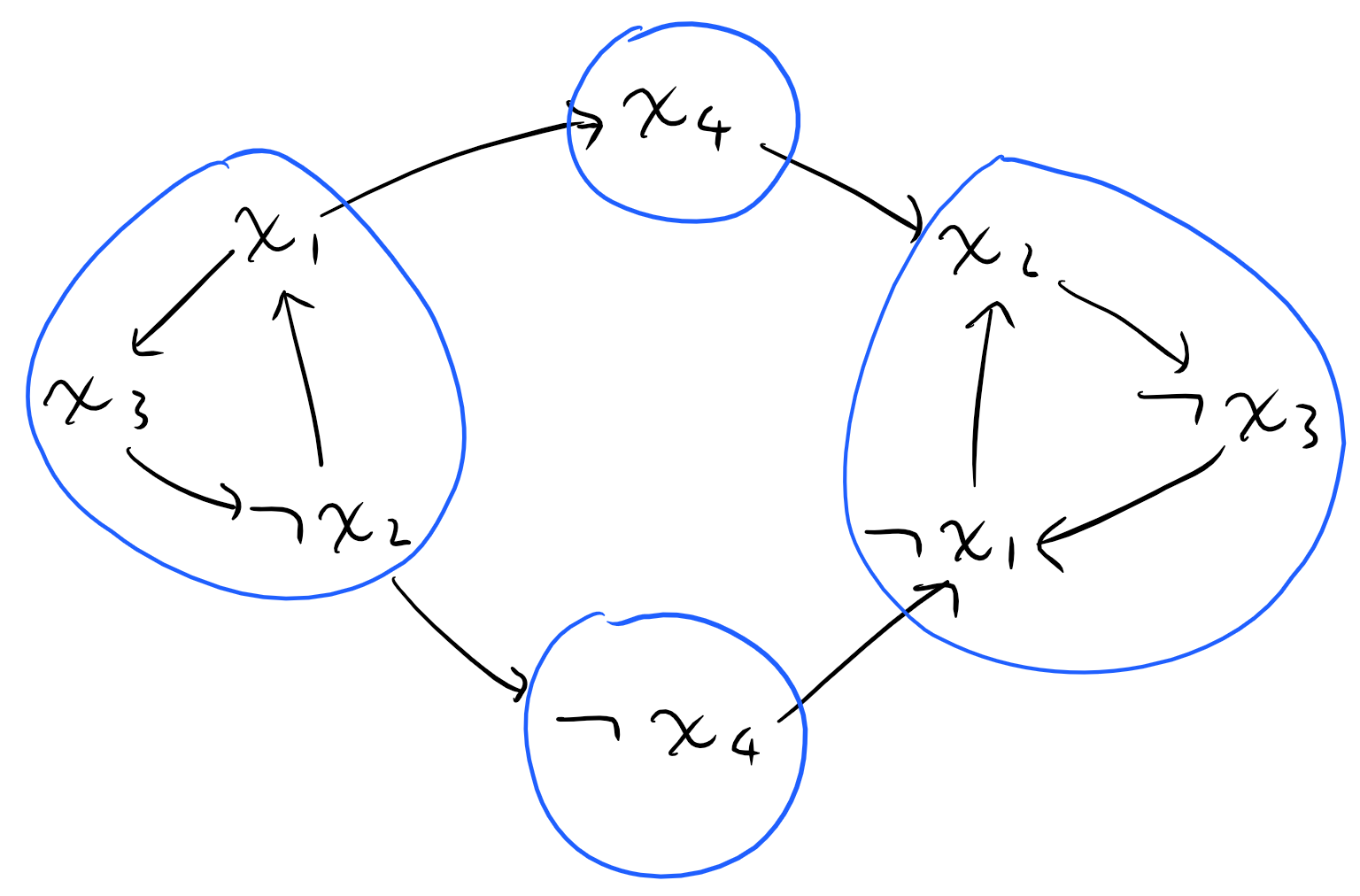
 는 다음 세 가지 중 한 가지 관계를 가집니다.
는 다음 세 가지 중 한 가지 관계를 가집니다.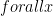 에 대해
에 대해  가 같은 컴포넌트에 속한다면
가 같은 컴포넌트에 속한다면  또한 같은 컴포넌트에 속하고, 이 특징을 이용해 위의 성질들을 증명할 수 있습니다.
또한 같은 컴포넌트에 속하고, 이 특징을 이용해 위의 성질들을 증명할 수 있습니다.