문제 개요
smcauth는 Rust로 작성된 garbled circuit 구현체의 취약점을 찾아 공격하는 문제였습니다. Crypto 카테고리로 출제되었으며 대회 종료까지 총 6팀이 해결했습니다. Garbled circuit, oblivious transfer, Rust 바이너리 리버싱, 패킷 로깅 스크립트 작성, 위장 RPC 클라이언트 작성 모두 이번 문제에서 처음으로 배우고 시도한 것들이었습니다. 다양한 지식을 익히고 시도하느라 정신 없었지만, 풀면서 굉장히 즐거운 문제였습니다. 대회 종료 15분을 남기고 아슬아슬하게 해결했는데, 팀원에게 “대회 때마다 항상 아쉽게 막타를 못 치더니 성장했다”라는 평을 들었습니다(…)
Garbled circuit은 두 사람이 서로의 입력값을 모르는 상태로, 신뢰할 수 있는 제삼자(trusted 3rd-party)의 존재 없이 부울 회로 형태로 작성된 함수의 결과를 계산하는 프로토콜입니다.
Garbled circuit 프로토콜의 개략적인 동작 순서는 다음과 같습니다. 위키피디아에 좀 더 자세하게 설명되어 있으니, write-up을 읽기 전 해당 프로토콜의 동작을 이해하고 오시는 것을 추천합니다.
- Garbler는 회로의 모든 와이어
에 대해 라벨
을 랜덤하게 생성합니다.
- Garbler는 회로의 각 게이트의 진리표를 대칭키 암호 등을 이용해 암호화해, evaluator가 진리표의 한 행만을 복호화 할 수 있도록 합니다. 예를 들어, 와이어
에서 입력을 받아 와이어
에 출력하는 XOR 게이트가 있을 때 이 게이트는
로 암호화 됩니다. 이를 garbling이라 부르며, 암호화된 회로를 garbled circuit이라 부릅니다.
- Garbler는 암호화된 회로 정보와 자신의 입력값에 해당하는 라벨을 evaluator에게 전송합니다. Evaluator는 1-2 oblivious transfer를 이용해 자신의 입력값에 해당하는 라벨을 garbler에게 요청합니다. Garbler가 가진 두 개의 라벨 중 evaluator는 단 하나의 값만을 획득할 수 있으며, garbler는 evaluator가 어떤 값을 획득했는지를 알 수 없는 전송 방식입니다.
- Evaluator는 자신과 garbler의 입력에 해당하는 라벨들을 이용해 garbled circuit 계산을 수행합니다. 이를 통해 회로의 최종 출력값에 대응되는 라벨(들)을 얻습니다. 마지막으로, evaluator와 garbler는 출력값의 라벨 정보를 공유해 회로의 실제 출력 결과를 알아냅니다.
Garbler는 oblivious transfer의 특성 때문에 evaluator의 입력값을 알 수 없습니다. Evaluator는 garbler의 입력에 해당하는 라벨을 가지고 있지만, 해당 라벨이 어느 값에 대응되는지를 알 수 없기 때문에 원래 입력값을 알 수 없습니다.
문제에서는 smcauth ELF 바이너리 파일 하나와 smcauth_syn.v 회로 파일 하나가 주어졌습니다. 바이너리는 verify와 auth 두 가지 모드로 동작하며, verify = garbler = server이며 auth = evaluator = client입니다. Garbled Circuit 프로토콜 자체가 안전함은 수학적으로 증명되어 있고, Rust 구현체에 문제가 있어 이를 공격해 서버 측의 비밀 키(회로 입력값)를 알아내는 문제라고 예상했습니다.
바이너리 실행 커맨드 예제는 다음과 같습니다.
./smcauth verify --netlist smcauth_syn.v --secret aaaaaaaabbbbbbbbccccccccdddddddd
바이너리는 Verilog 회로 파일 하나, 32자의 시크릿 키 하나를 입력으로 받으며 auth 모드에서는 --verifier 옵션으로 서버의 주소를 추가로 입력받습니다.
1. 입출력 관찰
로컬 환경 테스트를 통해, verify와 auth의 시크릿 키를 동일하게 입력할 경우 Jun 07 11:58:28.937 INFO authentication successful처럼 성공 메시지가 출력되며, 다르게 입력할 경우 Jun 07 11:58:40.923 WARN authentication failed처럼 실패 메시지가 출력되는 것을 확인했습니다.
모든 입력값을 OR하는 회로와 AND하는 회로 등 smcauth_syn.v 이외의 회로 파일을 시도해 보면서, netlist 옵션으로 입력하는 회로는 256 비트의 e_input과 g_input을 입력으로 받아 1 비트의 output을 출력해야 한다는 것을 확인했습니다. 또한, 회로의 output 비트가 1인 경우 “authentication successful” 메시지가 출력되는 것을 통해, smcauth_syn.v는 두 입력 값이 같은 경우 1을 출력하는 회로일 것이라 추측했습니다.
2. 패킷 분석
다음으로 수행한 것은 바이너리의 패킷 분석입니다. 먼저 Wireshark를 이용해 패킷에 TLS 등의 추가 암호화가 이루어지지 않음을 확인한 이후, Verify 프로세스와 auth 프로세스가 주고 받는 패킷을 전송과 수신으로 나누어 저장하는 Python 스크립트를 작성했습니다. 패킷 캡처 라이브러리인 pcap 등의 의존성 없이, strace 커맨드의 결과값을 파싱하는 방식으로 간단하게 작성했습니다.
바이너리에 포함된 문자열을 분석해 해당 바이너리가 RPC 프레임워크로 tarpc를 사용하고 있으며, 검색을 통해 tarpc는 serde의 bincode를 기본 직렬화 포맷으로 사용하고 있음을 알 수 있었습니다. 회로와 시크릿 값을 바꾸어 가며 수집한 패킷들을 비교 분석하며 휴먼러닝해 서버와 클라이언트가 주고 받는 패킷의 순서와 의미가 다음과 같음을 알아냈습니다.
- (전송 1) 세션 초기화 요청
- (수신 1) Proof of work 질의
- (전송 2) Proof of work 결과 전송
- (수신 2) Garbler 입력 라벨 정보
- (수신 2) Garbled circuit 정보
- (수신 2) Oblivious transfer를 위한 RSA 키
- (수신 2) Oblivious transfer를 위한 랜덤값
- (전송 3) Oblivious transfer를 이용한 evaluator 라벨 질의
- (수신 3) Evaluator 라벨 정보
- (전송 4) 결과 라벨 전송
- (수신 4) 라벨에 해당하는 결과값 수신
패킷을 분석하면서 라벨 생성이 시크릿 키에 의존하며 서로 다른 세션에서도 변하지 않는다는 것을 확인했지만, 이를 직접 익스플로잇에 이용하지는 않았습니다. RPISEC이나 upbhack 등 다른 팀은 이 특성을 이용해 디버거를 붙여 입력을 브루트포싱하는 방식으로 시크릿 키를 알아낸 것으로 보입니다.
저는 evaluator의 라벨 정보를 가져오는 RPC 프로시저를 두 번 호출해 evaluator의 모든 라벨을 알아내는 방식으로 접근했습니다. Evaluator의 모든 라벨을 알고 있다면 garbled circuit의 한 행만이 아니라 여러 행을 복호화 할 수 있고, 이를 반복해 필요한 모든 와이어의 상태를 복구할 수 있습니다. 이를 통해 출력 와이어를 원하는 결과로 만드는 입력값을 SMT solver를 이용해 역연산 하는 것을 목표로 삼았습니다.
3. 위장 RPC 클라이언트 작성
패킷 분석의 다음 단계는 RPC 프로시저를 두 번 호출하는 위장 RPC 클라이언트를 작성하고, 라벨과 회로 정보를 SMT solver가 취급하기 쉬운 형태로 출력하는 스크립트를 작성하는 것이었습니다. 패킷 분석을 통해 정보가 어떤 순서로 오고 가는지는 파악하고 있었으나, garbled circuit의 계산 및 oblivious transfer이 실제로 어떻게 이루어지는지는 패킷 분석만으로 알아낼 수 없기 때문에 바이너리를 리버스 엔지니어링 해야 했습니다.
삽질과 시행착오를 통해, 7A760이 oblivious transfer 관련 로직이며 2EE70이 garbled circuit 계산 관련 로직임을 알아냈습니다. 해당 함수를 분석해 다음 정보들을 알아냈습니다.
- RSA-based oblivious transfer는 Udacity의 Applied Cryptography 과목의 영상에 설명된 것과 동일하게 동작하는 것을 확인했습니다.
- Garbled circuit의 계산은 두 입력 라벨을 XOR한 결과를 AES-256의 키로 사용해, ECB + PKCS#7 모드로 블록을 복호화하고, 복호화된 블록의 길이가 32 바이트인 것을 체크한 뒤 해당 결과를 출력 라벨로 취급되는 것을 확인했습니다.
작성된 최종 스크립트는 다음과 같습니다.
첫 번째 통신인 proof of work 계산까지는 클라이언트와 서버 사이의 프록시로 작동하며 클라이언트의 입력값을 그대로 서버에 전달합니다(43~70행). 이를 통해 proof of work 리버싱을 건너뛸 수 있었으며, RPC 프로토콜에 사용되는 클라이언트 ID를 수집합니다(62행).
(수신 2)부터는 클라이언트에 의존하지 않고, 분석한 정보에 따라 패킷 역직렬화를 주도적으로 수행합니다(72~116행). 그 다음으로는 해당 스크립트의 핵심이라 할 수 있는 oblivious transfer를 두 번 호출하는 부분이 이어집니다(118~154행).
획득한 라벨을 이용해 garbled circuit 계산을 수행하고(188~208행), 이를 SMT solver가 다시 파싱하기 쉬운 형태로 출력합니다(210~229행). 이를 통해 출력된 SMT 정보는 다음과 같습니다.
해당 파일에서 e_input을 제외하고, 모든 와이어의 0과 1은 실제 입력값과는 상관 없이 임의로 붙인 변환값입니다. 이 변환을 통해 SMT solver를 호출하는 단에서는 라벨을 이용한 계산을 부울 함수 형태로 취급할 수 있습니다.
4. SMT solver
마지막 단계는 SMT solver를 이용해 회로의 출력을 1로 만드는 시크릿 키를 찾는 것입니다. z3의 Python 바인딩을 이용했습니다. 와이어 output의 0과 1 중 어느 것이 원래 회로의 1에 대응되는지 모르기 때문에, 두 가능성을 모두 시도해 보아야 합니다(44행).
OOO{m4by3_7ru57_1sn7_4lw4y5_b4d}
 로 나누어 떨어지는지 확인한다. 가로 분할선과 세로 분할선의 위치는 초콜릿 개수를 통해 독립적으로 판단 가능하며, 분할선들의 위치가 정해지면 분할된 각 칸에 초콜릿이 균등하게 들어가 있는지 확인한다.
로 나누어 떨어지는지 확인한다. 가로 분할선과 세로 분할선의 위치는 초콜릿 개수를 통해 독립적으로 판단 가능하며, 분할선들의 위치가 정해지면 분할된 각 칸에 초콜릿이 균등하게 들어가 있는지 확인한다.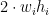 를 미리 P에서 빼고, 물건의 크기가
를 미리 P에서 빼고, 물건의 크기가  점수는
점수는 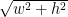 인 냅색을 수행한다.
인 냅색을 수행한다.